martes, 20 de marzo de 2018
lunes, 19 de marzo de 2018
Arquitectura física de una base de datos en SQL Server

La unidad fundamental del almacenamiento de datos en SQL Server es la página. El espacio en disco asignado a un archivo de datos (.mdf o .ndf) de una base de datos se divide lógicamente en páginas numeradas de forma contigua de 0 a n. Las operaciones de E/S de disco se realizan en el nivel de página. Es decir, SQL Server lee o escribe páginas de datos enteras.
Páginas
En SQL Server, el tamaño de página es de 8 KB. Esto significa que las bases de datos de SQL Server tienen 128 páginas por megabyte. Cada página empieza con un encabezado de 96 bytes, que se utiliza para almacenar la información del sistema acerca de la página. Esta información incluye el número de página, el tipo de página, el espacio libre en la página y el Id. de unidad de asignación del objeto propietario de la página.

En SQL Server, el tamaño de página es de 8 KB. Esto significa que las bases de datos de SQL Server tienen 128 páginas por megabyte. Cada página empieza con un encabezado de 96 bytes, que se utiliza para almacenar la información del sistema acerca de la página. Esta información incluye el número de página, el tipo de página, el espacio libre en la página y el Id. de unidad de asignación del objeto propietario de la página.
| Tipo de página | Contenido |
|---|---|
| Datos | Las filas de datos con todos los datos, excepto los datos text, ntext, image, nvarchar(max), varchar(max), varbinary(max) y xml, cuando text in row está establecido en ON. |
| Índice | Entradas de índice. |
| Texto o imagen | Tipos de datos de objetos grandes:
|
| Mapa de asignación global, Mapa de asignación global compartido | Información acerca de si se han asignado las extensiones. |
| Espacio disponible en páginas | Información acerca de la asignación de páginas y el espacio libre disponible en las páginas. |
| Mapa de asignación de índices | Información acerca de las extensiones utilizadas por una tabla o un índice por unidad de asignación. |
| Mapa cambiado masivamente | Información acerca de las extensiones modificadas por operaciones masivas desde la última instrucción BACKUP LOG por unidad de asignación. |
| Mapa cambiado diferencial | Información acerca de las extensiones que han cambiado desde la última instrucción BACKUP DATABASE por unidad de asignación. |
Las filas de datos se colocan en las páginas una a continuación de otra, empezando inmediatamente después del encabezado. Al final de la página, comienza una tabla de desplazamiento de fila y cada una de esas tablas contiene una entrada para cada fila de la página. Cada entrada registra la distancia del primer byte de la fila desde el inicio de la página. Las entradas de la tabla de desplazamiento de fila están en orden inverso a la secuencia de las filas de la página.
Extensiones
Las extensiones son la unidad básica en la que se administra el espacio. Una extensión consta de ocho páginas contiguas físicamente, es decir 64 KB. Esto significa que las bases de datos de SQL Server tienen 16 extensiones por megabyte.
Las extensiones son la unidad básica en la que se administra el espacio. Una extensión consta de ocho páginas contiguas físicamente, es decir 64 KB. Esto significa que las bases de datos de SQL Server tienen 16 extensiones por megabyte.
Para hacer que la asignación de espacio sea eficaz, SQL Server no asigna extensiones completas a tablas con pequeñas cantidades de datos. SQL Server tiene dos tipos de extensiones:
- Las extensiones uniformes son propiedad de un único objeto; sólo el objeto propietario puede utilizar las ocho páginas de la extensión.
- Las extensiones mixtas, que pueden estar compartidas por hasta ocho objetos. Cada una de las 8 páginas de la extensión puede ser propiedad de un objeto diferente.
Archivos de base de datos
Las bases de datos de SQL Server 2005 utilizan tres tipos de archivos:
Las bases de datos de SQL Server 2005 utilizan tres tipos de archivos:
- Archivos de datos principales: El archivo de datos principal es el punto de partida de la base de datos y apunta a los otros archivos de la base de datos. Cada base de datos tiene un archivo de datos principal. La extensión recomendada para los nombres de archivos de datos principales es .mdf.
- Archivos de datos secundarios: Los archivos de datos secundarios son todos los archivos de datos menos el archivo de datos principal. Puede que algunas bases de datos no tengan archivos de datos secundarios, mientras que otras pueden tener varios archivos de datos secundarios. La extensión de nombre de archivo recomendada para los archivos de datos secundarios es .ndf.
- Archivos de registro: Los archivos de registro almacenan toda la información de registro que se utiliza para recuperar la base de datos. Como mínimo, tiene que haber un archivo de registro por cada base de datos, aunque puede haber varios. La extensión de nombre de archivo recomendada para los archivos de registro es .ldf.
Páginas de archivo de datos
Las páginas de un archivo de SQL Server 2005 están numeradas secuencialmente, comenzando por 0 para la primera página del archivo. Cada archivo de una base de datos tiene un número de identificador único. Para identificar de forma única una página de una base de datos, se requiere el identificador del archivo y el número de la página.
Archivos de instantáneas de bases de datos
La forma de archivo que utiliza una instantánea de base de datos para almacenar sus datos de copia por escritura depende de si la instantánea la ha creado un usuario o se utiliza internamente:
La forma de archivo que utiliza una instantánea de base de datos para almacenar sus datos de copia por escritura depende de si la instantánea la ha creado un usuario o se utiliza internamente:
- Una instantánea de base de datos que crea un usuario almacena sus datos en uno o más archivos dispersos. La tecnología de archivos dispersos es una característica del sistema de archivos NTFS. Al principio, un archivo disperso no incluye datos de usuario y no se le asigna espacio en disco.
- Las instantáneas de bases de datos las utilizan internamente algunos comandos DBCC. Entre estos comandos se incluyen: DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC y DBCC CHECKFILEGROUP. Una instantánea de base de datos interna utiliza secuencias de datos alternativos dispersos de los archivos de base de datos originales.
Arquitectura del manejador de bases de datos Oracle

Archivos
- Control (ctl): almacenan información acerca de la estructura de archivos de la base.
- Rollback (rbs): cuando se modifica el valor de alguna tupla en una transacción, los valores nuevos y anteriores se almacenan en un archivo, de modo que si ocurre algún error, se puede regresar (rollback) a un estado anterior.
- Redo (rdo): bitácora de toda transacción, en muchos dbms incluye todo tipo de consulta incluyendo aquellas que no modifican los datos.
- Datos (dbf): el tipo más común, almacena la información que es accesada en la base de datos.
- Indices (dbf) (dbi): archivos hermanos de los datos para acceso rápido.
- Temp (tmp): localidades en disco dedicadas a operaciones de ordenamiento o alguna actividad particular que requiera espacio temporal adicional.
Memoria
- Shared Global Area (SGA): es el área más grande de memoria y quizás el más importante.
- Shared Pool: es una caché que mejora el rendimiento ya que almacena parte del diccionario de datos y el parsing de algunas consultas en SQL.
- Redo Log Buffer: contiene un registro de todas las transacciones dentro de la base, las cuales se almacenan en el respectivo archivo de Redo y en caso de siniestro se vuelven a ejecutar aquellos cambios que aún no se hayan reflejado en el archivo de datos (commit).
- Large Pool: espacio adicional, generalmente usado en casos de multithreading y esclavos de I/O.
- Java Pool: usado principalmente para almacenar objetos Java.
- Program Global Area (PGA): información del estado de cursores/apuntadores.
- User Global Area(UGA): información de sesión, espacio de stack.
Procesos
- System Monitor: despierta periódicamente y realiza algunas actividades entre las que se encuentran la recuperación de errores, recuperación de espacio libre en tablespaces y en segmentos temporales.
- Process Monitor: limpia aquellos procesos que el usuario termina de manera anormal, verificando consistencias, liberación de recursos, bloqueos.
- Database Writer: escribe bloques de datos modificados del buffer al disco, aquellas transacciones que llegan a un estado de commit.
- Log Writer: escribe todo lo que se encuentra en el redo log buffer hacia el redo file.
- Checkpoint: sincroniza todo lo que se tenga en memoria, con sus correspondientes archivos en disco.
jueves, 15 de marzo de 2018
Programa de multiplicación de números de 2 cifras
;EMU8086.model small ;Modelo de memoria .stack .data ;Definicion de datos(variables), donde se almacenara informacion .code ;Variables del primer numero ingresado unidades_n1 db ? decenas_n1 db ? ;Variables del segundo numero ingresado unidades_n2 db ? decenas_n2 db ? ;Variables temporales para los resultados de la primera multiplicacion res_temp_dec_n1 db ? res_temp_cen_n1 db ? ;Variables temporales paara los resultados de la segunda multiplicacion res_temp_dec_n2 db ? res_temp_cen_n2 db ? ;Variables para los resultados res_unidades db ? res_decenas db ? res_centenas db ? res_uni_millar db ? ;Variable de acarreo en multiplicacion acarreo_mul db 0 ;Variable de acarreo en suma acarreo_suma db 0 .startup ;cls mov ah,00h ;Function(Set video mode) mov al,03 ;Mode 80x25 8x8 16 int 10h ;Interruption Video mov ah,01h ;Function(character read) int 21h ;Interruption DOS functions sub al,30h ;ajustamos valores mov decenas_n1,al ;[chr1].chr2 * chr3 = ac.r1.r2 mov ah,01h ;Function(character read) int 21h ;Interruption DOS functions sub al,30h ;Ajustamos valores mov unidades_n1,al ;chr1.[chr2] * chr3 = ac.r1.r2 mov ah,02h ;Function(character to send to standard output) mov dl,'*' ;Character to show int 21h mov ah,01h ;Function(Read character) int 21h ;Interruption DOS Functions sub al,30h ;Transform(0dec = 30hex) mov decenas_n2,al ;chr1.chr2 * [chr3] = ac.r1.r2 mov ah,01h ;Function(Read character) int 21h ;Interruption DOS Functions sub al,30h ;Transform(0dec = 30hex) mov unidades_n2,al mov ah,02h ;Character to send to standar output mov dl,'=' ; int 21h ;Interruption DOS functions ;Realizamos las operaciones ;Primera multiplicacion ; Explicacion utilizando la multiplicacion de 99*99 ->(n1*n2) mov al,unidades_n1 ; al=9 mov bl,unidades_n2 ; bl=9 mul bl ; 9*9=81 -> (al=81) mov ah,00h ; AAM ; Separa el registro ax en su parte alta y baja mov acarreo_mul,ah ; acarreo_mul = 8 mov res_unidades,al ; res_unidades= 1 -> Reultado de unidades ;Segunda multiplicacion mov al,decenas_n1 ; al=9 mov bl,unidades_n2 ; bl=9 mul bl ; 9*9=81 -> (al=81) mov res_temp_dec_n1,al ; res_temp_dec_n1= 81 mov bl,acarreo_mul ; bl= 8 add res_temp_dec_n1,bl ; res_temp_dec_n1= 81+8= 89 mov ah,00h ; mov al,res_temp_dec_n1 ; al= 89 AAM ; Separa el registro ax en su parte alta y baja mov res_temp_cen_n1,ah ; res_temp_cen_n1= 8 mov res_temp_dec_n1,al ; res_temp_dec_n1= 9 ;Tercera multiplicacion ; Resultado actual = 000>1 mov al,unidades_n1 ; al= 9 mov bl,decenas_n2 ; bl= 9 mul bl ; 9*9=81 -> (al=81) mov ah,00h ; AAM ; Separa el registro ax en su parte alta y baja mov acarreo_mul,ah ; acarreo_mul= 8 mov res_temp_dec_n2,al ; res_temp_dec_n2= 1 ; mov bl, res_temp_dec_n1 ; bl= 9 add res_temp_dec_n2,bl ; res_temp_dec_n2= 1+9= 10 mov ah,00h ; mov al, res_temp_dec_n2 ; al = 10 AAM ; Separa el registro ax en su parte alta y baja mov acarreo_suma, ah ; acarreo_suma = 1 mov res_decenas,al ; res_decenas = 0 -> Reultado de decenas ;Tercera multiplicacion ; Resultado actual = 00>01 mov al,decenas_n1 ; al= 9 mov bl,decenas_n2 ; bl= 9 mul bl ; 9*9=81 -> (al=81) mov res_temp_cen_n2,al ; res_temp_cen_n2= 81 mov bl,acarreo_mul ; bl= 8 add res_temp_cen_n2,bl ; res_temp_cen_n2= 89 mov ah,00h ; mov al,res_temp_cen_n2 ; al= 89 AAM ; Separa el registro ax en su parte alta y baja mov res_uni_millar,ah ; res_uni_millar = 8 mov res_temp_cen_n2,al ; res_temp_cen_n2= 9 ; mov bl, res_temp_cen_n1 ; bl= 8 add res_temp_cen_n2, bl ; res_temp_cen_n2= 17 mov bl, acarreo_suma ; bl= 1 add res_temp_cen_n2,bl ; res_temp_cen_n2= 17+1= 18 mov ah,00h ; mov al,res_temp_cen_n2 ; al= 18 AAM ; mov acarreo_suma,ah ; acarreo_suma= 1 mov res_centenas,al ; res_centenas= 8 -> Resultado de centenas ; Resultado actual= 0>801 mov bl, acarreo_suma ; bl= 1 add res_uni_millar, bl ; res_uni_millar= 8+1= 9 -> Resultado de unidades de millar ; Reultado actual 9801 ;Mostramos resultados mov ah,02h mov dl,res_uni_millar add dl,30h int 21h mov ah,02h mov dl,res_centenas add dl,30h int 21h mov ah,02H mov dl,res_decenas add dl,30h int 21h mov ah,02H mov dl,res_unidades add dl,30h int 21h .exit end
martes, 13 de marzo de 2018
Memoria de una base de datos

Área Global del Sistema (System Global Area, SGA)
El Área Global del Sistema (SGA) es un grupo de estructuras de la memoria compartida que contiene datos e información de control de una instancia de una BD. Si varios usuarios se conectan de forma concurrente a la misma instancia, entonces los datos se comparten en el SGA, por lo que también se llama shared global area.
Una
instancia en Oracle se compone de un SGA y de procesos. Cuando se crea
una instancia, Oracle asigna memoria a un SGA automáticamente y esta se
devuelve al sistema operativo cuando la instancia se cierra. Por tanto,
cada instancia posee su propio SGA.
Una
parte del SGA contiene información general acerca del estado de la base
de datos y de la instancia, a la que los procesos en segundo plano
necesitan acceder (SGA fija), pero no se almacenan los datos de usuario. El SGA también incluye información de comunicación entre procesos, como la información de bloqueos.
Buffer Cache (o Database Buffer Cache)
Su función es mantener bloques de datos más recientemente leídos directamente de los archivos de datos, esto se hace para un mejor desempeño pues si los datos son de nuevo requeridos por un usuario, su acceso es más rápido.
Cuando se procesa una consulta, el servidor busca los bloques de datos requeridos en esta estructura. Si el bloque no se encuentra en esta estructura, el proceso servidor lee el bloque de la memoria secundaria y coloca una copia en esta estructura. De esta forma, otras peticiones que requieran de este bloque de datos no requerirán de acceso a memoria secundaria (lecturas físicas).
Los bloques pueden contener datos modificados que no son permanentemente escritos a disco y los cuales maneja Oracle de una manera consistente para atender la concurrencia de los usuarios conectados a la base de datos, dichos usuarios comparten el acceso a esta área. Los bloques modificados se llamas bloques sucios.
Área de SQL Compartido, Shared SQL Pool
En esta zona se encuentran las sentencias SQL que han sido analizadas. El análisis sintáctico de las sentencias SQL lleva su tiempo y Oracle mantiene las estructuras asociadas a cada sentencia SQL analizada durante el tiempo que pueda para ver si puede reutilizarlas.
Antes de analizar una sentencia SQL, Oracle mira a ver si encuentra otra sentencia exactamente igual en la zona de SQL compartido. Si es así, no la analiza y pasa directamente a ejecutar la que mantiene en memoria. De esta manera se premia la uniformidad en la programación de las aplicaciones. La igualdad se entiende que es lexicográfica, espacios en blanco y variables incluidas.
La base de datos Oracle asigna memoria a la shared pool cuando una nueva instrucción sql se analiza. El tamaño de esta memoria depende de la complejidad de la instrucción. Si toda la shared pool ya ha sido asignada la base de datos Oracle puede liberar elementos de la shared pool hasta que haya suficiente espacio libre para nuevas sentencias. Al liberar un elemento de la shared pool el sql asociado debe ser recompilado y reasignado a otra área de sql compartida la próxima vez que se ejecute.
El contenido de la zona de SQL compartido es:
- Las sentencias SQL y PL/SQL (texto de la sentencia)
- Plan de ejecución de la sentencia SQL.
- Lista de objetos referenciados.
Large Pool
El administrador de la base de datos puede configurar esta área de memoria opcional, para proveer localidades más amplias de memoria para:
- Memoria de sesiones.
- Procesos de I/O del servidor
- Backups de la base de datos y operaciones de recuperación.
Al asignar espacios dentro de large pool para un servidor compartido,
Oracle puede usar la shared pool principalmente para guardar en caché
las sentencias compartidas de sql y evitar la sobrecarga causada por la
disminución de la caché de sql compartida. Además la memoria para backup
y operaciones de recuperación y para procesos de I/O del servidor es
asignada en buffers de algunos cientos de kilobytes, por lo que la large
pool mucho más capaz de satisfacer dicha demanda de memoria que la
shared pool.
Java Pool
La memoria java pool es usada en la memoria del servidor para todas las sesiones que utilicen código java y datos en la JVM. Esta memoria es usada de diferentes maneras dependiendo del modo en el que la base de datos esté corriendo.
Algunas de las cuales son:
- Análisis sintáctico de código y scripts en Java.
- Tareas de instalación relacionada con aplicaciones Java.
- Procedimientos almacenados de código Java.
La Java Pool utiliza el algoritmo LRU (Least-Recently-Used), el cual se encarga de mantener en memoria el código Java que se utiliza con mayor frecuencia.
Loop que imprime letras de colores - Aportación de Emanuel Horta
;EMU8086
BIOS EQU 10H
DOS EQU 21H
FIN EQU 4C00H
.DATA
TITULO DB 'Agnax & Alizz '
COLORES DB 5BH
DB 5FH
DB 5BH
DB 5FH
DB 5BH
DB 00H
DB 0F0H
DB 00H
DB 09CH
DB 09FH
DB 09CH
DB 09FH
DB 09CH
DB 00H
DB 0CH
.CODE
INICIO PROC NEAR:
MOV AX, @DATA
MOV DS, AX
;Esta parte de aqui no es necesaria
INT BIOS
MOV CX, 15
BUCLE:
;Ponemos esto para no agarrar basura
MOV DX,SI
ADD DX,35 ;Columna
MOV DH, 12 ;Renglon
CALL COLOCA
MOV AL, [SI+OFFSET TITULO]
MOV BL, [SI+OFFSET COLORES]
CALL COLOR
INC SI
LOOPNZ BUCLE
MOV AH, 0
INT DOS
CALL COLOCA
MOV AX, FIN
INT DOS
COLOR PROC
MOV AH, 9
INT BIOS
RET
COLOCA PROC
MOV AH,2
INT BIOS
RET
END INICIO

;Turbo Assembler
.MODEL SMALL
PILA SEGMENT STACK
DB 64 DUP('PILA ')
PILA ENDS
BIOS EQU 10H
DOS EQU 21H
FIN EQU 4C00H
DATO SEGMENT
TITULO DB 'Agnax & Alizz '
COLORES DB 5BH
DB 5FH
DB 5BH
DB 5FH
DB 5BH
DB 00H
DB 0F0H
DB 00H
DB 09CH
DB 09FH
DB 09CH
DB 09FH
DB 09CH
DB 00H
DB 0CH
DATO ENDS
CODIGO SEGMENT
ASSUME DS:DATO, CS:CODIGO, SS:PILA
INICIO PROC NEAR
MOV AX, DATO
MOV DS, AX
;Esta parte de aqui no es necesaria
INT BIOS
MOV CX, 15
BUCLE:
;Ponemos esto para no agarrar basura
MOV DX,SI
ADD DX,35 ;columna
MOV DH,12 ;renglon
CALL COLOCA
MOV AL, [SI+OFFSET TITULO]
MOV BL, [SI+OFFSET COLORES]
CALL COLOR
INC SI
LOOPNZ BUCLE
MOV AH,0
INT DOS
CALL COLOCA
MOV AX, FIN
INT DOS
COLOR PROC
MOV AH, 9
INT BIOS
RET
COLOCA PROC
MOV AH,2
INT BIOS
RET
END INICIO
CODIGO ENDS

miércoles, 7 de marzo de 2018
Componentes de un Sistema Gestor de Bases de Datos
Un sistema de bases de datos se divide en módulos que se encargan de cada una de las responsabilidades del sistema completo.
Los componentes funcionales de un sistema de bases de datos se pueden dividir a grandes rasgos en:

Usuarios
Los componentes funcionales de un sistema de bases de datos se pueden dividir a grandes rasgos en:

Usuarios
- Normales: Usuarios que no requieren preparación especial en el manejo de base de datos y que utilizan el sistema a través de programas de aplicación que han sido escritos para ellos.
- Programadores de aplicaciones: Usuarios de la base de datos y escriben programas de aplicación. Pueden llegar a utilizar herramientas DRA (Desarrollo Rápido de Aplicaciones), con las que pueden crear formularios e informes con poco esfuerzo de programación.
- Sofisticados: Son quienes utilizan la base de datos a través de consultas escritas en un lenguaje de consultas.
- DBA: Su función es administrar la base de datos por lo tanto tiene acceso total.
Componentes de procesamiento de consultas
- Compilador de LMD: Traduce las instrucciones del LMD en lenguaje de consultas a instrucciones a bajo nivel que entiende el motor de evaluación de consultas.
- Precompilador del LMD incorporado: Convierte las instrucciones de LMD incorporadas en un programa de aplicación en llamadas a procedimientos normales en el lenguaje anfitrión.
- Intérprete del LDD: Interpreta las instrucciones del LDD y las registra en un conjunto de tablas que contiene metadatos.
- Motor de evaluación de consultas: Ejecuta las instrucciones a bajo nivel generadas por el compilador del LMD.
Componentes de gestión de almacenamiento
- Gestor de autorización e integridad: Comprueba que se satisfagan las ligaduras de integridad y la autorización de los usuarios para acceder a los datos.
- Gestor de transacciones: Asegura que la base de datos quede en un estado consistente a pesar de los fallos del sistema, y que las ejecuciones de transacciones concurrentes ocurran sin conflicto.
- Gestor de archivos: Gestiona la reserva de espacio de almacenamiento de disco, y las estructuras de datos usadas para representar la información almacenada en disco.
- Gestor de memoria intermedia: Es responsable de traer los datos del disco de almacenamiento a memoria principal y decidir qué datos tratar en la memoria caché.
Almacenamiento en disco
- Diccionario de datos: Dentro de él se encuentra la lista de todos los elementos que forman parte del flujo de datos de todo el sistema. Almacena el conjunto de esquemas y especifica cada archivo y su ubicación, también incluye información acerca de qué programas utilizan qué datos, y a que usuarios les interesa un informe u otro.
- Indices: Que se utilizan para buscar más rápidamente un registro. Estos, junto con los datos estadísticos son archivos que son almacenados en disco.













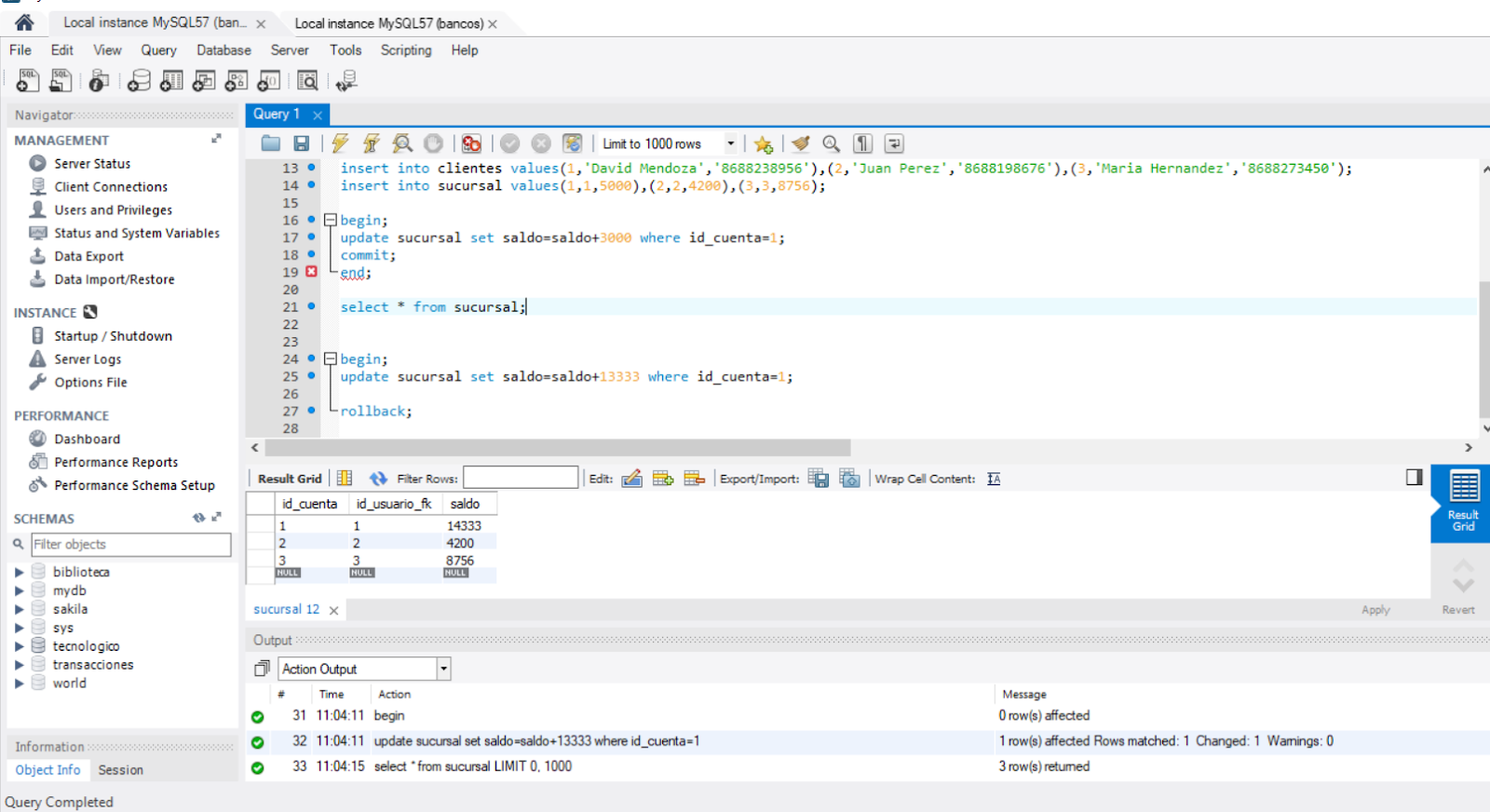

jueves, 1 de marzo de 2018
Tarea: Ejemplo de loop
;Turbo Assembler
.model small
.stack 64
datos segment
mensaje db "Ingresa el numero de veces que se repetira el mensaje (1-9)",13,10,'$'
repetir db 13,10,"Repitiendo el ciclo $"
datos ends
codigo segment
assume cs:codigo, ds:datos
inicio:
mov ax, datos
mov ds, ax
mov ah, 09
lea dx, mensaje
int 21h
mov ah, 01
int 21h
sub al, 30h
mov cl, al
ciclo:
mov ah, 09
lea dx, repetir
int 21h
loop ciclo
mov ax,4c00h
int 21h
codigo ends
end inicio
;EMU8086.model small .stack 64 .data mensaje db "Ingresa el numero de veces que se repetira el mensaje (1-9)",13,10,'$' repetir db 13,10,"Repitiendo el ciclo $" .code inicio proc far mov ax, @data mov ds, ax mov ah, 09 lea dx, mensaje int 21h mov ah, 01 int 21h sub al, 30h mov cl, al ciclo: mov ah, 09 lea dx, repetir int 21h loop ciclo mov ax,4c00h int 21h inicio endp end
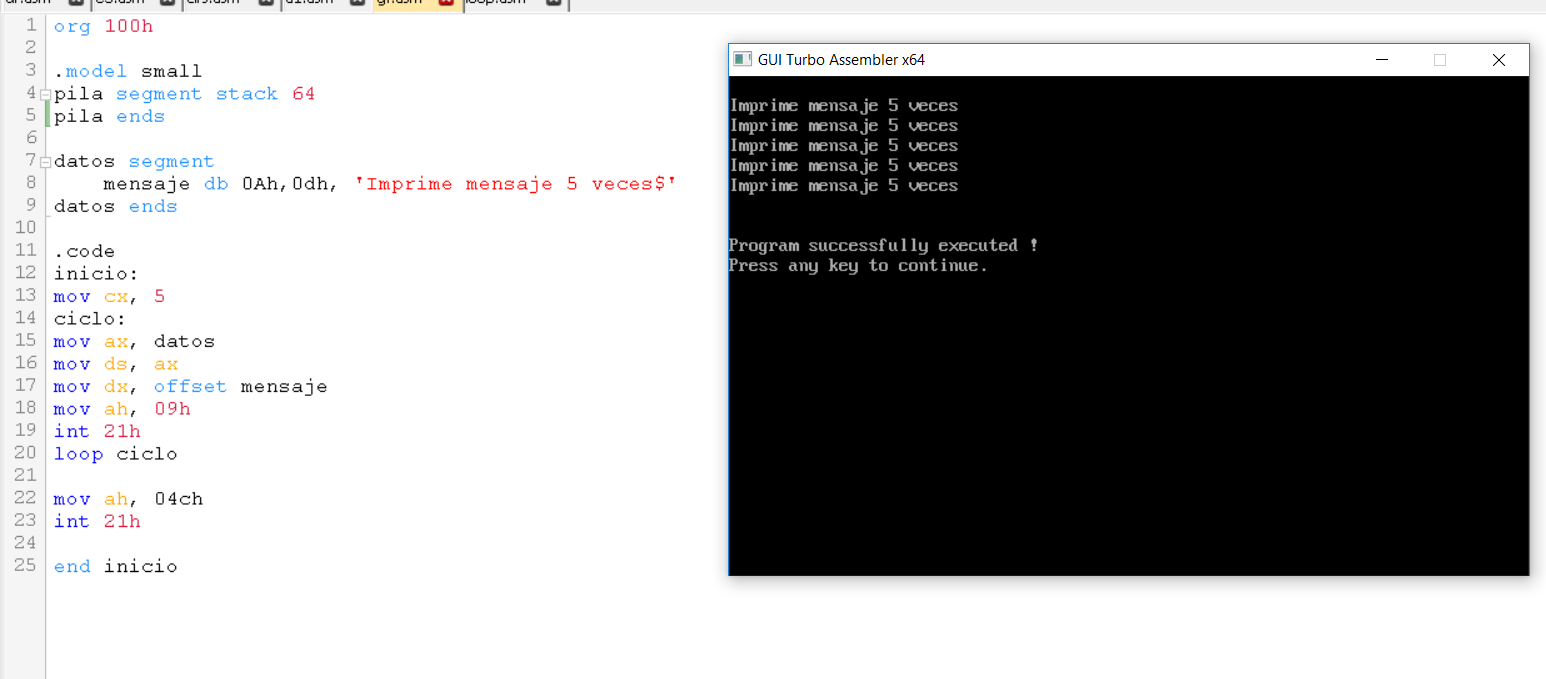

Suscribirse a:
Entradas (Atom)