Objetivo de la Unidad
-Conocer los diferentes tipos de memoria y procesos que nos podemos encontrar en un sistema gestor de bases de datos.
-Tener conocimiento sobre el procedimiento de instalación y configuración de un DBMS.
-Saber los requisitos que pide cada DBMS y comandos generales de alta y baja.
-Poder elegir el mejor DBMS en cada situación.
2.1. Características del DBMS
Los sistemas de administración de bases de datos son usados para permitir a los usuarios acceder y manipular la base de datos proveyendo métodos para construir sistemas de procesamiento de datos para aplicaciones que requieran acceso a los datos.
Además proporcionan a los administradores las herramientas que les permitan ejecutar tareas de mantenimiento y administración de los datos.
Control de la redundancia de datos
Este consiste en
lograr una mínima cantidad de espacio de almacenamiento para
almacenar los datos evitando la duplicación de la información. De
esta manera se logran ahorros en el tiempo de procesamiento de la
información, se tendrán menos inconsistencias, menores costos
operativos y hará el mantenimiento más fácil.
Compartimiento de datos
Una de las
principales características de las bases de datos, es que los datos
pueden ser compartidos entre muchos usuarios simultáneamente,
proveyendo, de esta manera, máxima eficiencia.
Mantenimiento de la integridad
La integridad de los
datos es la que garantiza la precisión o exactitud de la información
contenida en una base de datos. Los datos interrelacionados deben
siempre representar información correcta a los usuarios.
Soporte para Control
de transacciones y recuperación de fallas
Se conoce como
transacción toda operación que se haga sobre la base de datos. Las
transacciones deben por lo tanto ser controladas de manera que no
alteren la integridad de la base de datos. La recuperación de fallas
tiene que ver con la capacidad de un sistema DBMS de recuperar la
información que se haya perdido durante una falla en el software o
en el hardware.
Independencia de los
Datos
En las aplicaciones
basadas en archivos, el programa de aplicación debe conocer tanto la
organización de los datos como las técnicas que el permiten acceder
a los datos. En los sistemas DBMS los programas de aplicación no
necesitan conocer la organización de los datos en el disco duro.
Este totalmente independiente de ello.
Seguridad
La disponibilidad de
los datos puede ser restringida a ciertos usuarios. Según los
privilegios que posea cada usuario de la base de datos, podrá
acceder a mayor información que otros.
2.1.3 Requerimientos
para instalación de la base de datos
Antes de instalar
cualquier SGBD es necesario conocer los requerimientos de hardware y
software, el posible software a desinstalar previamente, verificar el
registro de Windows y el entorno del sistema, así como otras
características de configuración especializadas como pueden ser la
reconfiguración de los servicios TCP/IP y la modificación de los
tipos archivos HTML para los diversos navegadores.
2.1.4 Instalación
del software de base de datos en modo transaccional
Una
base de datos en modo transaccional significa que la BD será capaz
de que las operaciones de inserción y actualización se hagan dentro
de una transacción, es un componente que procesa información
descomponiéndola de forma unitaria en operaciones indivisibles,
llamadas transacciones, esto quiere decir que todas las operaciones
se realizan o no, si sucede algún error en la operación se omite
todo el proceso de modificación de la base de datos, si no sucede
ningún error se hacen toda la operación con éxito.
Una
transacción es un conjunto de líneas de un programa que llevan
insert o update o delete. Todo aquél software que tiene un log de
transacciones (que es la "bitácora" que permite hacer
operaciones de commit o rollback), propiamente es un software de BD;
aquél que no lo tiene (v.g. D-Base), propiamente no lo es. Todo
software de base de datos es transaccional; si el software de la BD
no es "transaccional", en realidad NO es un "software"
de BD; en todo caso, es un software que emula el funcionamiento de un
verdadero software de BD. Cada transacción debe finalizar de forma
correcta o incorrecta como una unidad completa. No puede acabar en un
estado intermedio.
Se
usan las siguientes métodos :
Y
depende que base de datos uses para efectuar las operaciones pero, es
la misma teoría para cualquier BD.
2.1.5
Variables de ambiente y archivos importantes para instalación
Variables
de Ambiente: Se usan para personalizar el entorno en el que se
ejecutan los programas y para ejecutar en forma correcta los comandos
del shell.
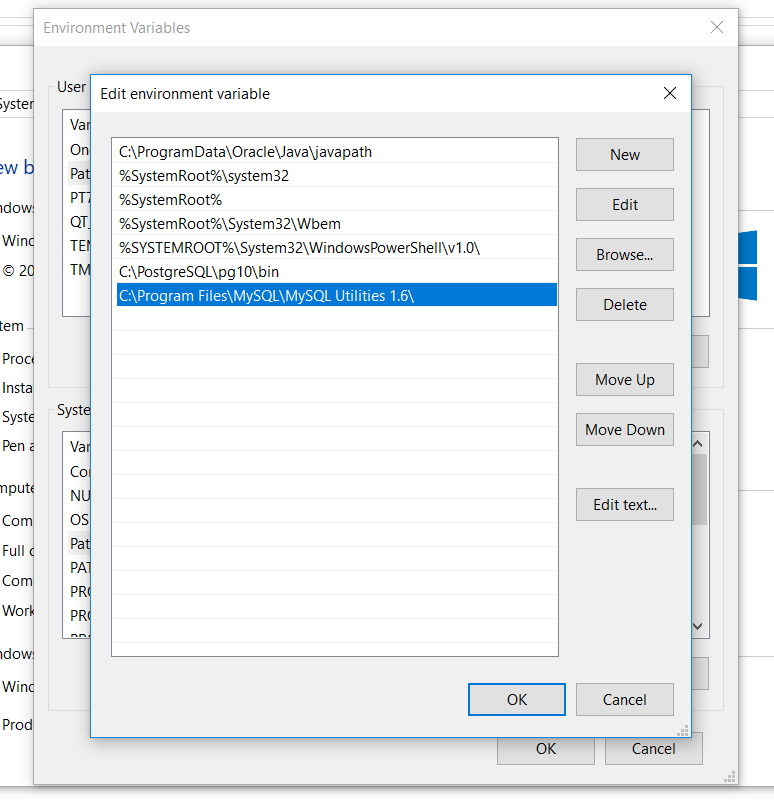
Variables de entorno declaradas por el instalador de MySQL en Windows 10:
Carpeta de archivos de MySQL en Windows 10:
A
continuación se comentan las opciones más utilizadas de la sección
mysqld (afectan al funcionamiento del servidor MySQL), se almacenan
en el archivo my.cnf (o my.ini).
basedir
= ruta: Ruta a la raíz MySQL.
console:
Muestra los errores por consola independientemente de lo que se
configure para log_error.
datadir
= ruta: Ruta al directorio de datos.
default-table-type
= tipo: Tipo de la Tabla InnoDB o, MyISAM.
flush:
Graba en disco todos los comandos SQL que se ejecuten (modo de
trabajo, sin transacción).
general-log
= valor: Con valor uno, permite que funcione el archivo LOG para
almacenar las consultas realizadas.
general-log-file
= ruta: Indica la ruta al registro general de consultas.
language:
Especifica el idioma de los lenguajes de error, normalmente esots
archivos de lenguaje, están bajo /usr/local/share.
log-error
= ruta: Permite indicar la ruta al registro de errores.
log
= ruta: Indica la ruta al registro de consultas.
long-query-time
= n: Segundos a partir de los cuales una consulta que tardes más, se
considerará una consulta lenta.
og-bin
= ruta: Permite indicar la ruta al registro binario.
pid-file
= ruta: Ruta al archivo que almacena el identificador de proceso de
MySQL.
port
= puerto: Puerto de escucha de MySQL.
skip-grant-tables:
Entra al servidor saltándose las tablas de permisos, es decir todo
el mundo tiene privilegios absolutos.
skip-networking:
El acceso a MySQL se hará solo desde el servidor local.
slow-query-log
= 0|1: Indica si se hace LOG de las consultas lentas.
slow-query-log-file
= ruta: Ruta al archivo que hace LOG de las consultas lentas.
socket
= ruta: Archivo o nombre de socket a usar en las conexiones locales.
standalone:
Para Windows, hace que el servidor no pase a ser un servicio.
user
= usuario: Indica el nombre de usuario con el que se iniciará sesión
en MySQL.
tmpdir
= ruta: Ruta al directorio para archivos temporales.
2.1.6
Procedimiento general de instalación de un DBMS (Firebird)
2.1.7
Procedimiento para Configuración de un DBMS
Para
configurar nuestro DBMS podemos acceder a las siguientes pantallas,
para Oracle o MySQL. El esquema de una base de datos (en inglés,
Database Schema) describe la estructura de una Base de datos, en un
lenguaje formal soportado por un Sistema administrador de Base de
datos (DBMS). En una Base de datos Relacional, el Esquema define sus
tablas, sus campos en cada tabla y las relaciones entre cada campo y
cada tabla.
Oracle
generalmente asocia un 'username' como esquemas en este caso SYSTEM y
HR (Recursos humanos).
Por
otro lado MySQL presenta dos esquemas information_schema y MySQL
ambos guardan información sobre privilegios y procedimientos del
gestor y no deben ser eliminados.
Optamos
por Detailed Configuration, de modo que se optimice la configuración
del servidor MySQL.
Dependiendo
del uso que vayamos a darle a nuestro servidor deberemos elegir una
opción u otra, cada una con sus propios requerimientos de memoria.
Puede que te guste la opción Developer Machine, para
desarrolladores, la más apta para un uso de propósito general y la
que menos recursos consume. Si vas a compartir servicios en esta
máquina, probablemente Server Machine sea tu elección o, si vas a
dedicarla exclusivamente como servidor SQL, puedes optar por
Dedicated MySQL Server Machine, pues no te importará asignar la
totalidad de los recursos a esta función.
De
nuevo, para un uso de propósito general, te recomiendo la opción
por defecto, Multifunctional Database.
InnoDB
es el motor subyacente que dota de toda la potencia y seguridad a
MySQL. Su funcionamiento requiere de unas tablas e índices cuya
ubicación puedes configurar. Sin causas de fuerza mayor, acepta la
opción por defecto.
Esta
pantalla nos permite optimizar el funcionamiento del servidor en
previsión del número de usos concurrentes. La opción por defecto,
Decision Support (DSS) / OLAP será probablemente la que más te
convenga.
Deja
ambas opciones marcadas, tal como vienen por defecto. Es la más
adecuada para un uso de propósito general o de aprendizaje, tanto si
eres desarrollador como no. Aceptar conexiones TCP te permitirá
conectarte al servidor desde otras máquinas (o desde la misma
simulando un acceso web típico).
Hora
de decidir qué codificación de caracteres emplearás, salvo que
quieras empezar a trabajar con Unicode porque necesites soporte
multilenguaje, probablemente Latin1 te sirva (opción por defecto).
Instalamos
MySQL como un servicio de Windows (la opción más limpia) y lo
marcamos para que el motor de la base de datos arranque por defecto y
esté siempre a nuestra disposición. La alternativa es hacer esto
manualmente.
Además,
me aseguro de marcar que los ejecutables estén en la variable PATH,
para poder invocar a MySQL desde cualquier lugar en la línea de
comandos.
Pon
una contraseña al usuario root. Esto siempre es lo más seguro.
Si
lo deseas, puedes indicar que el usuario root pueda acceder desde una
máquina diferente a esta, aunque debo advertirte de que eso tal vez
no sea una buena práctica de seguridad.
Última
etapa, listos para generar el fichero de configuración y arrancar el
servicio.
Sólo
damos al botón de Finalizar y terminamos con la configuración del
DBMS.
2.1.8
Comandos Generales de Alta y Baja del DBMS
Una
tabla es un sistema de elementos de datos (atributo - valores) que se
organizan que usando un modelo vertical - columnas (que son
identificados por su nombre)- y horizontal filas. Una tabla tiene un
número específico de columnas, pero puede tener cualquier número
de filas. Cada fila es identificada por los valores que aparecen en
un subconjunto particular de la columna que se ha identificado por
una llave primaria.
Definiendo
cómo es almacenada la información
CREATE DATABASE se utiliza para crear una nueva base de datos vacía.
DROP DATABASE se utiliza para eliminar completamente una base de
datos existente.
CREATE TABLE se utiliza para crear una nueva tabla, donde la
información se almacena realmente.
ALTER TABLE se utiliza para modificar una tabla ya existente.
DROP TABLE se utiliza para eliminar por completo una tabla existente.
Manipulando
los datos
SELECT
se utiliza cuando quieres leer (o seleccionar) tus datos.
INSERT se utiliza cuando quieres añadir (o insertar) nuevos datos.
UPDATE se utiliza cuando quieres cambiar (o actualizar) datos
existentes.
DELETE se utiliza cuando quieres eliminar (o borrar) datos
existentes.
REPLACE se utiliza cuando quieres añadir o cambiar (o reemplazar)
datos nuevos o ya existentes.
TRUNCATE se utiliza cuando quieres vaciar (o borrar) todos los datos
de la plantilla.
Conclusiones de la unidad
Los sistemas gestores de bases de datos nacieron para facilitar el desarrollo y avance de las empresas. Sabemos también que la información crecía día a día, y conforme iba creciendo Surgieron necesidades, que eran preciso suplir para mantener a flote la Empresa en el mundo moderno donde la información es la base del éxito.
Los recursos utilizados por los SGBD van desde una red, maquina, hasta sistemas operativos, pero su funcionamiento varía muy poco dependiendo de las cualidades que tengan dichos recursos, de cualquier modo el propósito del SGBD sigue siendo el mismo: Administrar Información. Con esto en mente empezaremos la descripción del funcionamiento de los SGBD para entender y conceptualizar las ventajas del uso de estas herramientas tan útiles y versátiles para nosotros como futuros ingenieros de sistemas.